What I learned by simulating fake humans inside a computer
This is what happens when you give a research psychologist a coding environment and a Joshua Epstein quote. I discovered agent-based computational social science and immediately built a simulation.

“If you didn’t grow it, you didn’t explain it.”
- Joshua Epstein, Generative Social Science: Studies in agent-based computational modeling
No, this post isn’t about Tron. And it isn’t about the Matrix, even though a part of me wishes it was. But you should have seen the look on my face when I first read that quote from Joshua Epstein. This was a few weeks ago. I was poking around the web for books and research papers on organizations. You know, doing some homework. When I randomly stumbled on the concept of generative computational social science. A mouthful, I know. But what a wonderful mouthful it was.
You better believe I rabbit holed. Fast. I went deeper than Alice did in Wonderland. How had I never heard of this field? All these years spent dusting off books in the library and surfing Google Scholar like it was the only site on the World Wide Web, and never, not once had this magical concept come my way. I guess I had to become a proper tech nerd first (thanks Shopify). Only then was I ready to receive the insights that would inspire the prototype I’m about to show you today.
Of course after the dopamine in my brain subsided, I was left only with the vivid memory of inspiration. This always happens to me. Awe. Fascination. Then, reality. Now what? Where do I even start. I’ve never simulated something like this before. That’s ok. I have tools. I have curiosity. I have stubbornness and endurance. And snacks. That’s always a good place to start.
Let me be honest with you. My brain loves complexity. I thrive in it. I seek it. That’s why I’m obsessed with tackling impossible problems. I studied consciousness and imagination for crying out loud. There are many upsides to this. I don’t shy away from a challenge. But I can also tend to overengineer, especially when what I’m working on is ambiguous.
Over the years, I’ve come to appreciate the genius of simplicity. It is an art. It is a science. It is everything worth pursuing. But before I can simplify, I have to be messy. I have to play around with the complexity.
With lots of practice and patience, I became really good at moving fast through the cycle of inspiration → messy exploration → complex solution → simplified solution. But being honest about who I am and how my brain works was key. It unlocked so much confidence for me. I can translate complex ideas and systems into elegant and simple artifacts, solutions, and stories. But I also know to give myself permission to play in the mud first.
My goal for today is to play in that mud, but just a little bit. I’m also writing for you, my dear reader. So I can’t be too messy. My hope is to give you a peak into how I approach a vague problem, and what I think about when I tinker through it, so that you might gain some insights about your own creativity and way of thinking too. I also hope to teach you a thing or two about computational simulations. But given I don’t know much about it either, we’ll have to learn together!
Alright, let’s simulate some computational people.
First, a (very) brief overview
Generative social science is a way of studying how large, complex social patterns emerge from the small, simple behaviors of individuals. The field traces back to Joshua Epstein and Robert Axtell’s 1996 book Growing Artificial Societies, which introduced a model called Sugarscape. Their goal was to understand why wealth distribution tends towards inequality within a free society. In their simulation, sugar was the resource.
The Sugarscape model starts with agents (not AI, but personas that you program) in a two-dimensional grid environment. Each agent started the simulation with simple rules for how to move, eat, and interact.1
The results (over many rounds of simulation) showed that fundamental collective behaviors like group formation, cultural transmission, combat, and trade, had emerged. Nobody programmed those patterns in. They grew. How fascinating!
Which humans should I simulate?
Why not test my own thinking? In my last essay, I theorized about three types of people I think are becoming increasingly valuable as organizations change. People I called crystallizers, propagators, and diffusers2. If you want to know more about their personalities, I suggest you go read that post first.
The goal of my simulation would (ideally) be pretty simple. Start from the three people I theorized about, and let the organizational patterns emerge from the bottom up. I decided to mimic the Sugarscape ‘rules of the game’ as closely as possible, and only add on or shake things up if absolutely necessary. I’ll go into those details soon. But first…
Look at my simulation!
Yes, I’m showing you the results of my simulation before I explain my approach. How gauche. Why would I do that? Because I want to hook you in. I know. I’m revealing all my secrets.
You can find the HuggingFace simulation here (that’s what I’m running in the video, can you see my little people moving around?!). You can also find the GitHub repo with all the code here.3
Now, time to break it all down
Ok now that you’re shaking with awe and anticipation, let me get into the really fun stuff.
The board
A 20×20 grid. Think of it like a chess board where work problems and people coexist and move around each other. Why 20x20 when Sugarscape had 50x50? My choice wasn’t an exact science, but I had less total agents than Sugarscape, and only 30 problems. I wanted to start smaller. But not so small that agents would be on top of each other within 5 simulations. A 2:1 agent to problem ratio felt ok enough to try things out.
The problems
I decided on 30 problems and scattered them randomly across the space. Because for this part I literally had no clue. It felt right. No one should start at an advantage. Maybe next simulation, I can program in some penalties and bonuses and such.
Each problem has a single property that matters: its definition level, which is a number between 0 and 1.
0 = pure formlessness. Nobody has named this yet. There’s no scope, no brief, no direction. Just a vague sense that something needs to happen.
1 = fully defined. The problem has enough shape to be deemed solved (or about to be solved).
Problems start at random definition levels too because like I said, I have zero mental model at this point. I set some problems to be nearly formed, some completely undefined.
When a problem reaches 1.0, it’s solved, disappears, and a new one appears in its place starting at (once again) a random definition level, to keep things evened out.
The agents
With 30 problems, I wanted to make sure that agents weren’t all converging on the same one, but not so few agents that they spent the whole simulation just traveling and rarely interacting. With 15 agents and 30 problems, roughly every agent would have about two problems close to them at any time. That felt like enough variety to create interesting movement. Or so I thought. I don’t really know.
Each agent starts with a random position in the space because no one is at an advantage. They all get a contribution score (how many successful interactions they had), and a counter for how many simulation rounds they spent without making progress (how long since they last contributed).
Crystallizer
Moves toward problems with low definition (< 0.4). When close enough, they raise the definition level by 0.25.
That gets them a contribution point of +1, because they were successful in manifesting their purpose, which is to create a bit more clarity.
Propagator
Their first priority is to move towards any agent that hasn’t made progress in 5+ rounds of simulation (looks like the proper lingo is ‘steps’ for those of you taking notes).
When close enough, they reset the other agent’s stuck counter and frees them up. For that, they get a contribution of +1.
If nobody is stuck, they move toward ambiguous problems (0.3–0.7) and raise their definition by 0.15. They also get a contribution point of +1 for that.
Diffuser
Moves toward any agent who has been drifting (stuck for 3+ steps).
When close enough, they reduce the stuck counters of all nearby agents, so their impact is more widespread than propagators on other agents (they coordinate and create structure across agents).
They get a contribution point of +1 per coordination event.
The movement rules
Each simulation round, every agent scans the space for the nearest target that matches their behavioral profile and moves one step toward it. If they’re close enough to interact, they interact. If not, they keep moving and their steps-without-progress counter ticks up.
The order in which agents act each round is randomized too. No agent always goes first. This prevents any single agent from dominating early and keeps the dynamics neutral (which is the reasoning I’ve been using this whole time, no favorites).
The scenarios
I wanted to have a bit of extra fun and see if different compositions of the same three shapes (15 agents total per scenario so the comparisons are fair) produced different outcomes.
Crystallizer-heavy (8 crystallizers, 4 propagators, 3 diffusers)
What happens when you load up the environment with people that take ambiguous problems and turn them into form (but don’t actively seek out to unblock others by asking questions, or create structure for groups of people)? Does the formless backlog disappear, or do you hit diminishing returns?
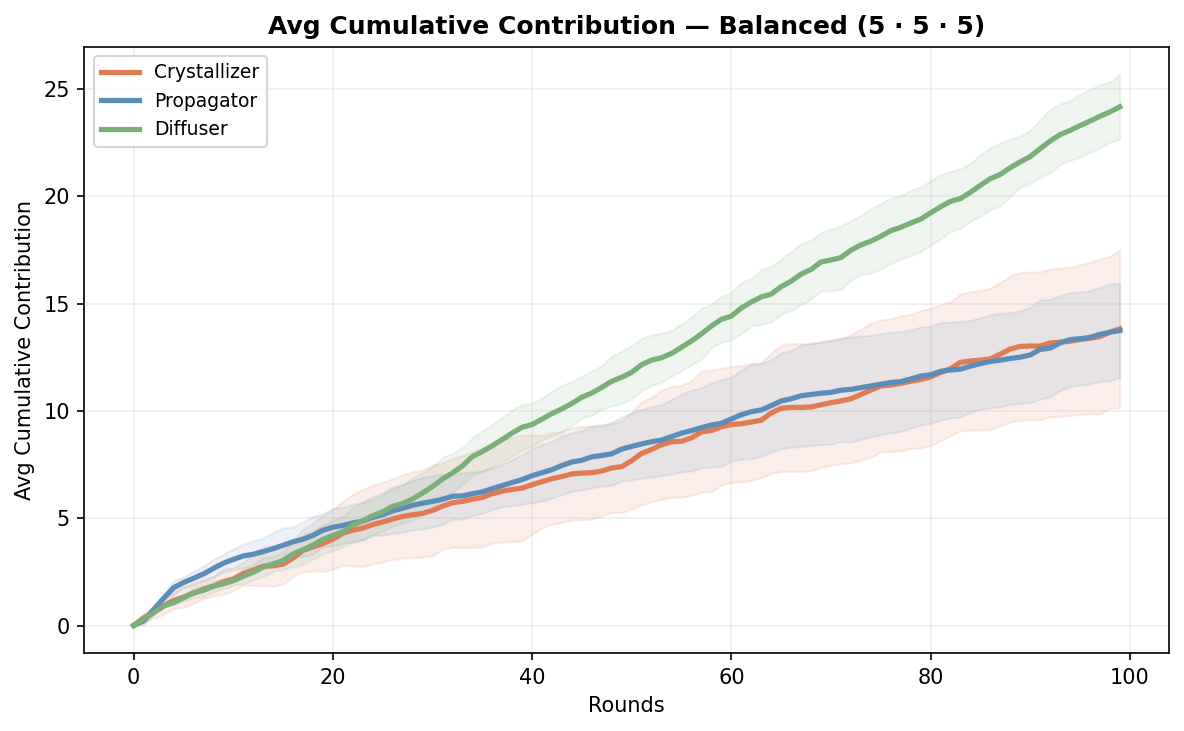
Balanced (5 of each)
The obvious hypothesis and the scenario I was originally going to run by itself. Equal distribution, even playing field, but unrealistic in the real world.
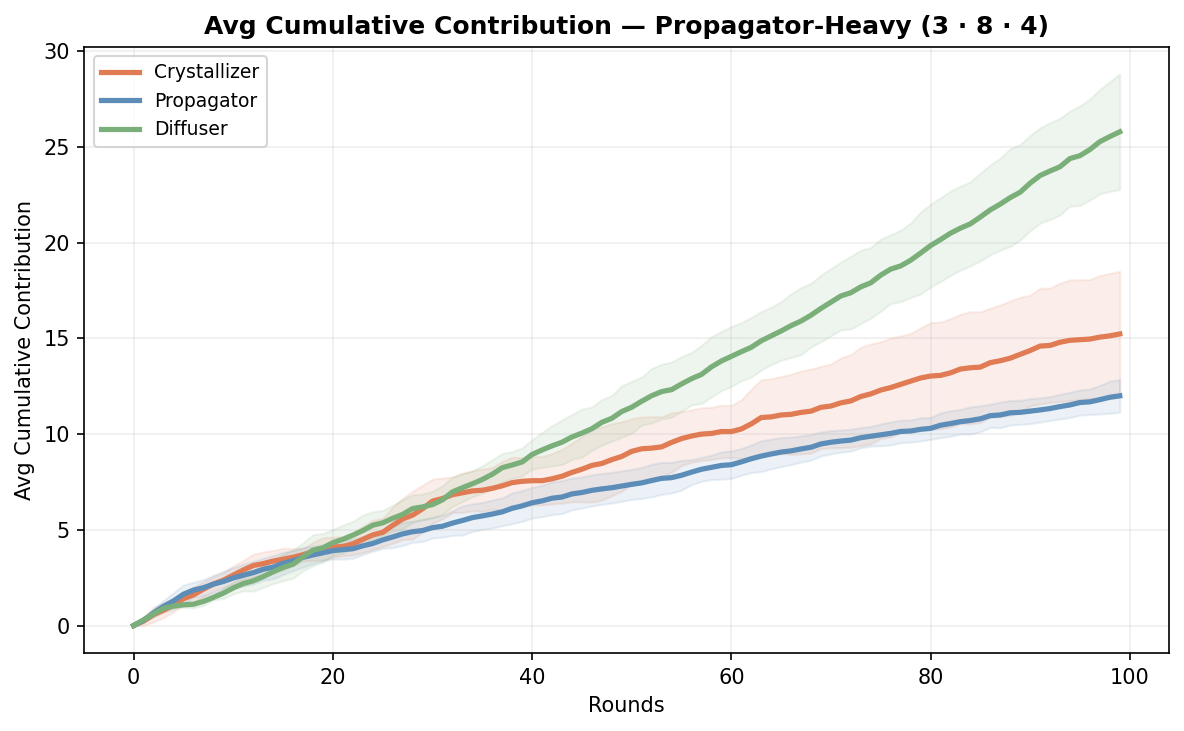
Propagator-heavy (3 crystallizers, 8 propagators, 4 diffusers)
What happens when the team is dominated by reframers? Do things move faster, or does formless work just pile up waiting for a crystallizer who isn’t there?
I didn’t do a diffuser-heavy scenario because I thought 3 was already enough, and diffusers (in my opinion) are likely more rare to come by, so it didn’t feel very realistic. I’m also the least certain about how I encoded their behavioral rules, so I want to run a few scenarios first to see what comes out.
What the simulation is tracking
Over 10 simulations of 100 rounds each, I’m tracking three things to find emerging patterns (if you’re using my HuggingFace interactive simulator though, every time you press ‘play’, that’s one simulation. You can press it as many times as you want and see where things go. But every simulation is 100 rounds).
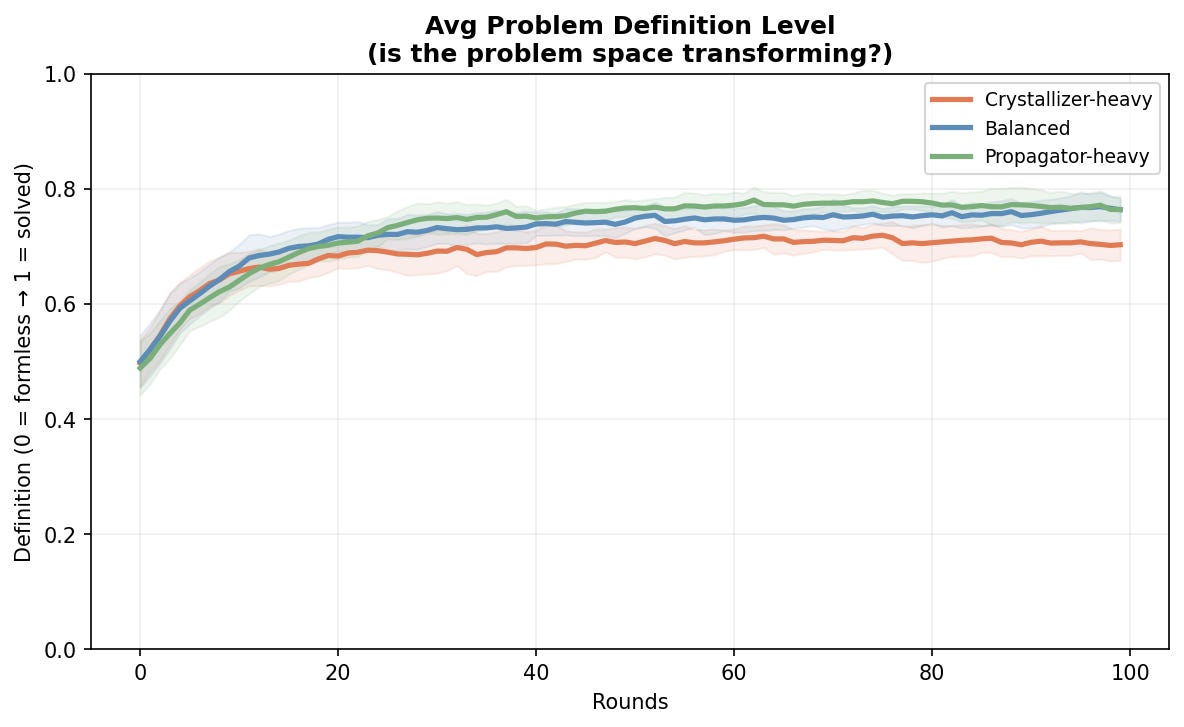
Average problem definition
Is the problem space actually transforming? Are formless problems getting shape over time, or is the team spinning in place? This is the primary question.
Formless backlog
How many undefined problems (definition < 0.3) are sitting untouched for 5+ steps?
A low backlog means the team is picking up undefined work as it arrives. A growing backlog means formlessness is accumulating faster than anyone is giving it shape.
Solved count
How many problems actually reached full definition and crossed the finish line? This is completion. An organization that has low completion isn’t getting anything done.
All of the cool things I learned
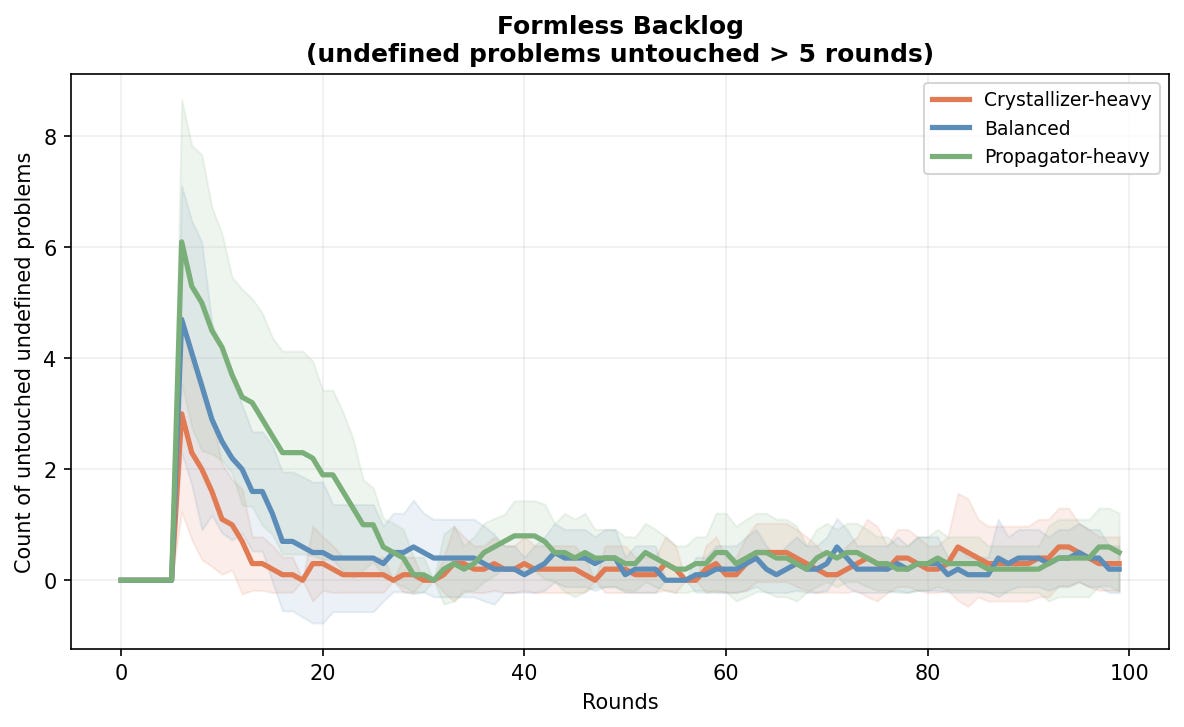
The crystallizer-heavy team was best at reducing ambiguity and solving problems. With eight crystallizers, the formless backlog stayed the lowest (average of 0.40), and you can see that formlessness gets resolved more quickly earlier on in the rounds (sharp drop by about round 15 or so).
More problems got fully solved than any other scenario (33 on average over 10 runs of 100 rounds).
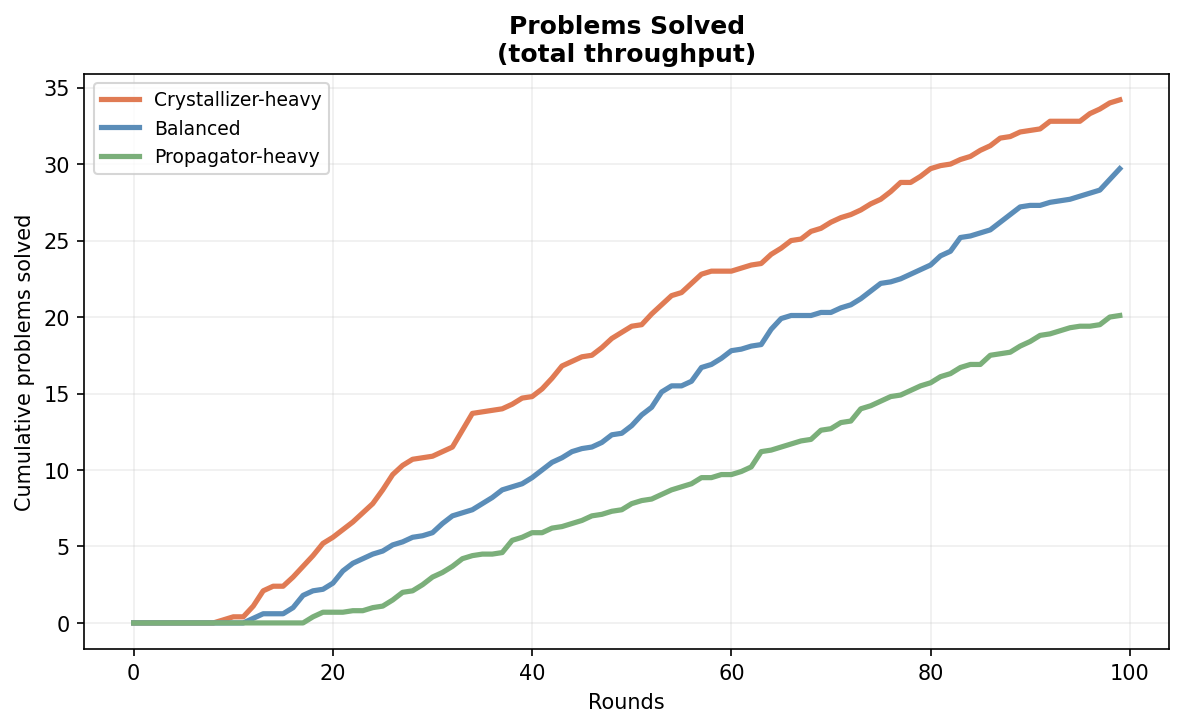
This makes sense because crystallizers move directly toward undefined problems and raise their definition level more than other agent types. More of them means more ambiguous work gets picked up. The formlessness doesn’t pile up as fast.
But here’s what I didn’t expect as much: individual crystallizers contributed less overall in the crystallizer-heavy team than in the balanced or propagator-heavy one.
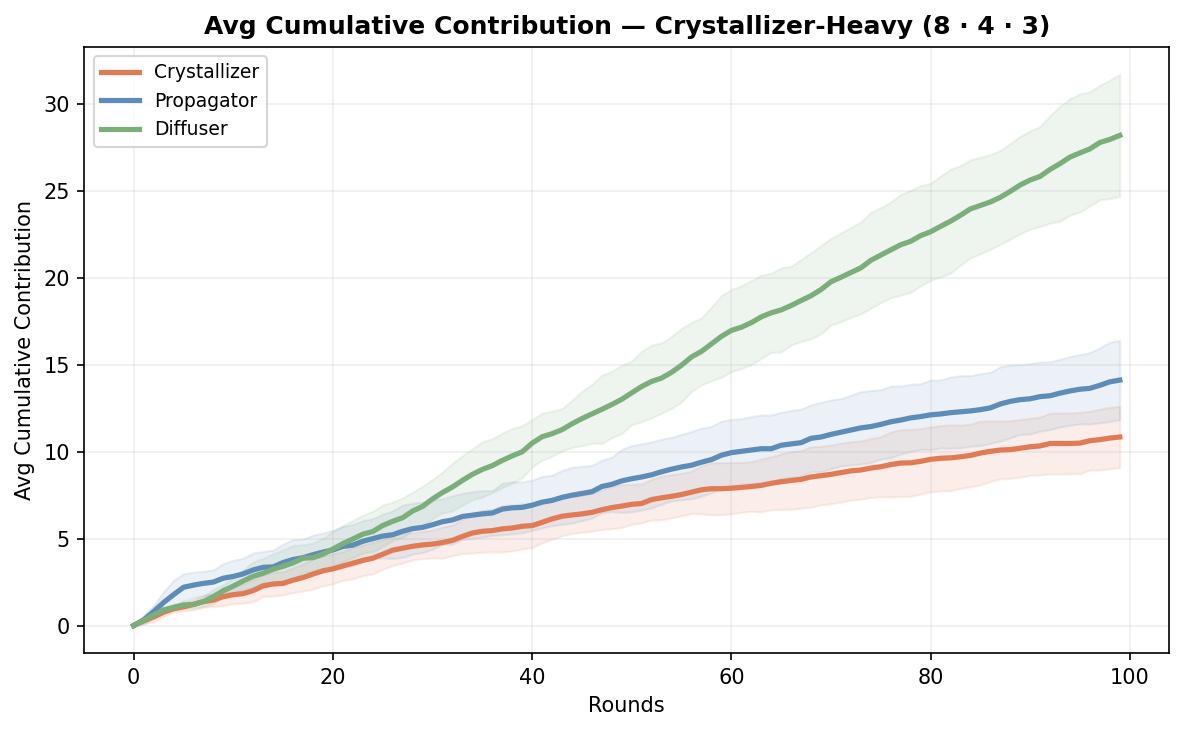
When you have eight crystalizers chasing 30 problems, they’re competing for the same pool of undefined work. They bump into each other. Some of them spend more time in transit than interacting. The team produces more, but each individual crystallizer does less. Their role has lower leverage as you increase their numbers.
The propagator-heavy team left the most formless work untouched, with a backlog of 0.60 on average, 1.5 times the crystallizer-heavy team. But the problems that did get worked on reached the highest average definition level (0.78). Although all scenarios were relatively close on this one.
This also makes sense. Propagators don’t seek formless problems. Their first priority is stuck agents. If nobody is stuck, they look for problems that already have a bit of shape. Truly undefined work sits there waiting for a crystallizer who isn’t there in large enough numbers. The propagator-heavy team is good at advancing things that are already in motion. It’s not built to pick up raw formlessness as well.
The balanced team wasn’t best at anything. But it was consistently alright across all three. Second or close on every metric. No single shape could dominate because the mix kept pulling in different directions. Crystallizers giving form, propagators reframing stuck work, diffusers keeping everyone coordinated.
I’d be curious to see what a balanced approach might look like over a longer period of time, and with more rules set to simulate a broader spectrum of real-life org challenges. I think other scenarios would eventually get ahead. This balanced scenario just doesn’t feel productive long-term to me.
One thing this version also doesn’t measure is total team output. That would be an interesting next version. A team-level impact metric that aggregates across all agents and compares total output. Combined with experiments on team composition.
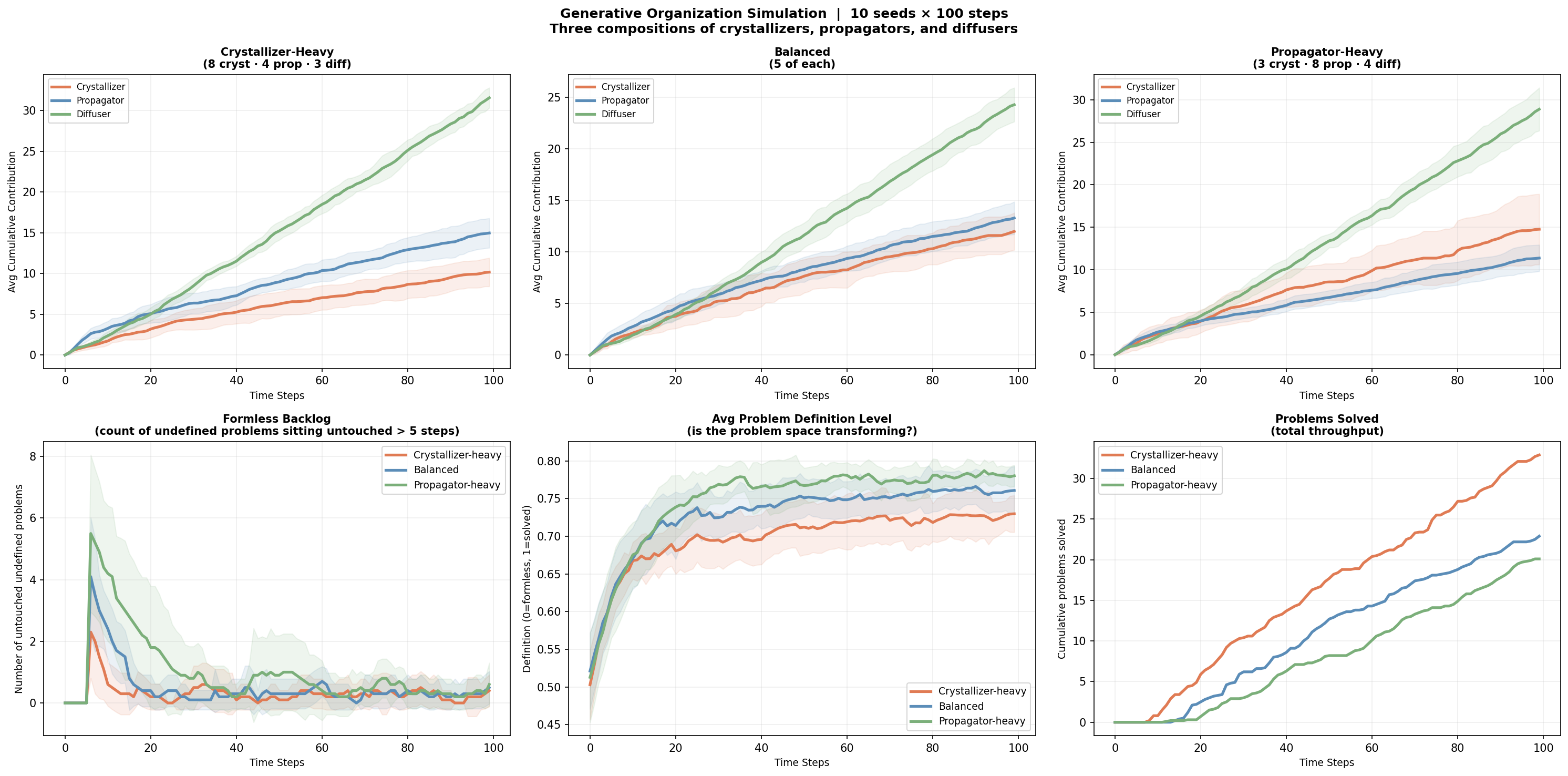
Last but not least, there’s the diffuser. Across all three compositions, the diffuser accumulated the highest average contribution score. Every scenario. By a meaningful margin in some cases. I want to be careful about this finding, because I think it’s at least partly an artifact of how I decided to program the rules.
The diffuser was the hardest shape to model. Their value is ambient and relational. They don’t raise a problem’s definition level directly. They don’t reframe a stuck agent’s thinking right away. They hold the informal architecture together, and I found that hard to translate into a behavioral rule. The threshold I used to define “drifting” (3 steps without progress) might be too low. Agents regularly spend several steps just moving across the space, which would trigger the diffuser even when nobody is genuinely struggling. In other words, I may have over-counted the diffuser to compensate for the fact that their value is hard to measure.
What I can say is that the difficulty of encoding the diffuser in a simulation mirrors something real about how their value shows up in organizations. If I can’t cleanly measure coordination work in a model, maybe that’s telling me something about why organizations struggle to see it too. It’s real invisible work.
So, what’s next?
Well, I’m going to start by putting the simulation down because I have other things to do and this is proving to be very immersive. I want to tweak and play with this so much more. I feel similar to how I felt as a researcher. The more I play with the data, the more questions I have, and the more experiments I want to run. And simulations make that feel somewhat ‘easy’ because I don’t have to go collecting data. But the hard part is encoding the metrics in the right way.
But wow. This is fun, right? I hope you enjoyed this and feel empowered to try your own simulation too! Just try it on anything you have questions about. Start simple and don’t be afraid to make mistakes. You have my GitHub, go grab the code and modify it for yourself.
If you read this far, I’d love to get your thoughts in the comments too. What questions came up for you?
Happy building!
Each location on the grid had a resource capacity from 0 = completely depleted to 4 = fully loaded with sugar. Each agent had a set of attributes (e.g. genetic vision range, metabolic rate) that determined which resource zones they were attracted to. Agents moved toward the richest visible sugar peaks, harvested them, and changed the resource level of that grid cell to 0.
I initially wanted to also include the T and I shapes that I talked about in my very first essay. Because I wanted to compare them to the new shapes I created and see how they all interacted. But yes, you know where I’m going. That was too complex. I was trying to mix two frameworks together without knowing exactly how they actually connect. So the little software engineer on my should told me to simplify my system. Stick to what I’m actually trying to observe. My new shapes.
I used Mesa, which is Python’s open-source framework for agent-based models (ABMs), an alternative to older toolkits (NetLogo, Repast, MASON). You can use it with libraries like NumPy, pandas, Matplotlib, and machine learning environments, which makes it especially versatile. Plus did I mention, open-source? We love open-source software over in this corner of the internet (says I, Eve-Marie, as I type from my Ubuntu-clad computer).